
Empowering all developers to build without barriers
GitHub has been awarded the 2024 Axe Accessibility at Scale Award from Deque Systems. Read more about how we’ve implemented accessibility at scale.
Resque is our Redis-backed library for creating background jobs, placing those jobs on multiple queues, and processing them later. Background jobs can be any Ruby class or module that responds…
Resque is our Redis-backed library for creating background jobs, placing
those jobs on multiple queues, and processing them later.
Background jobs can be any Ruby class or module that responds to
perform. Your existing classes can easily be converted to background
jobs or you can create new classes specifically to do work. Or, you
can do both.
All the details are in the README. We’ve used it to process
over 10m jobs since our move to Rackspace and are extremely happy with it.
But why another background library?
We’ve used many different background job systems at GitHub. SQS,
Starling, ActiveMessaging, BackgroundJob, DelayedJob, and beanstalkd.
Each change was out of necessity: we were running into a
limitation of the current system and needed to either fix it or move
to something designed with that limitation in mind.
With SQS, the limitation was latency. We were a young site and heard
stories on Amazon forums of multiple minute lag times between push and
pop. That is, once you put something on a queue you wouldn’t be able
to get it back for what could be a while. That scared us so we moved.
ActiveMessaging was next, but only briefly. We wanted something
focused more on Ruby itself and less on libraries. That is, our jobs
should be Ruby classes or objects, whatever makes sense for our app,
and not subclasses of some framework’s design.
BackgroundJob (bj) was a perfect compromise: you could process Ruby
jobs or Rails jobs in the background. How you structured the jobs was
largely up to you. It even included priority levels, which would let
us make “repo create” and “fork” jobs run faster than the “warm some
caches” jobs.
However, bj loaded the entire Rails environment for each job. Loading
Rails is no small feat: it is CPU-expensive and takes a few
seconds. So for a job that may take less than a second, you could have
8 – 20s of added overhead depending on how big your app is, how many
dependencies it requires, and how bogged down your CPU is at that time.
DelayedJob (dj) fixed this problem: it is similar to bj, with a
database-backed queue and priorities, but its workers are
persistent. They only load Rails when started, then process jobs in a
loop.
Jobs are just YAML-marshalled Ruby objects. With some magic you can
turn any method call into a job to be processed later.
Perfect. DJ lacked a few features we needed but we added them and
contributed the changes back.
We used DJ very successfully for a few months before running into some
issues. First: backed up queues. DJ works great with small datasets,
but once your site starts overloading and the queue backs up (to, say,
30,000 pending jobs) its queries become expensive. Creating jobs can
take 2s+ and acquiring locks on jobs can take 2s+, as well. This means
an added 2s per job created for each page load. On a page that fires
off two jobs, you’re at a baseline of 4s before doing anything else.
If your queue is backed up because your site is overloaded, this added
overhead just makes the problem worse.
Solution: move to beanstalkd. beanstalkd is great because it’s fast,
supports multiple queues, supports priorities, and speaks YAML
natively. A huge queue has constant time push and pop operations,
unlike a database-backed queue.
beanstalkd also has experimental persistence – we need persistence.
However, we quickly missed DJ features: seeing failed jobs, seeing
pending jobs (beanstalkd only allows you to ‘peek’ ahead at the next
pending job), manipulating the queue (e.g. running through and
removing all jobs that were created by a bug or with a bad job name),
etc. A database-queue gives you a lot of cool features. So we moved
back to DJ – the tradeoff was worth it.
Second: if a worker gets stuck, or is processing a job that will take
hours, DJ has facilities to release a lock and retry that job when
another worker is looking for work. But that stuck worker, even
though his work has been released, is still processing a job that you
most likely want to abort or fail.
You want that worker to fail or restart. We added code so that,
instead of simply retrying a job that failed due to timeout, other
workers will a) fail that job permanently then b) restart the locked
worker.
In a sense, all the workers were babysitting each other.
But what happens when all the workers are processing stuck or long
jobs? Your queue quickly backs up.
What you really need is a manager: someone like monit or god who can
watch workers and kill stale ones.
Also, your workers will probably grow in memory a lot during the
course of their life. So you need to either make sure you never create
too many objects or “leak” memory, or you need to kill them when they
get too large (just like you do with your frontend web instances).
At this point we have workers processing jobs with god watching them
and killing any that are a) bloated or b) stale.
But how do we know all this is going on? How do we know what’s sitting
on the queue? As I mentioned earlier, we had a web interface which
would show us pending items and try to infer how many workers are
working. But that’s not easy – how do you have a worker you just
kill -9‘d gracefully manage its own state? We added a process to
inspect workers and add their info to memcached, which our web
frontend would then read from.
But who monitors that process. And do we have one running on each
server? This is quickly becoming very complicated.
Also we have another problem: startup time. There’s a multi-second
startup cost when loading a Rails environment, not to mention the
added CPU time. With lots of workers doing lots of jobs being
restarted on a non-trival basis, that adds up.
It boils down to this: GitHub is a warzone. We are constantly
overloaded and rely very, very heavily on our queue. If it’s backed
up, we need to know why. We need to know if we can fix it. We need
workers to not get stuck and we need to know when they are stuck.
We need to see what the queue is doing. We need to see what jobs have
failed. We need stats: how long are workers living, how many jobs are
they processing, how many jobs have been processed total, how many
errors have there been, are errors being repeated, did a deploy
introduce a new one?
We need a background job system as serious as our web framework.
I highly recommend DelayedJob to anyone whose site is not 50%
background work.
But GitHub is 50% background work.
In the Old Architecture, GitHub had one slice dedicated to processing
background jobs. We ran 25 DJ workers on it and all they did was run
jobs. It was known as our “utility” slice.
In the New Architecture, certain jobs needed to be run on certain
machines. With our emphasis on sharding data and high availability, a
single utility slice no longer fit the bill.
Both beanstalkd and bj supported named queues or “tags,” but DelayedJob
did not. Basically we needed a way to say “this job has a tag of X”
and then, when starting workers, tell them to only be interested in
jobs with a tag of X.
For example, our “archive” background job creates tarballs and zip
files for download. It needs to be run on the machine which serves
tarballs and zip files. We’d tag the archive job with “file-serve” and
only run it on the file serving slice. We could then re-use this tag
with other jobs that needed to only be run on the file serving slice.
We added this feature to DelayedJob but then realized it was an
opportunity to re-evaluate our background job situation. Did someone
else support this already? Was there a system which met our upcoming
needs (distributed worker management – god/monit for workers on
multiple machines along with visibility into the state)? Should we
continue adding features to DelayedJob? Our fork had deviated from
master and the merge (plus subsequent testing) was not going to be fun.
We made a list of all the things we needed on paper and started
re-evaluating a lot of the existing solutions. Kestrel, AMQP,
beanstalkd (persistence still hadn’t been rolled into an official
release a year after being pushed to master).
Here’s that list:
Can you name a system with all of these features:
I can. Redis.
If we let Redis handle the hard queue problems, we can focus on the
hard worker problems: visibility, reliability, and stats.
And that’s Resque.
With a web interface for monitoring workers, a parent / child forking
model for responsiveness, swappable failure backends (so we can send
exceptions to, say, Hoptoad), and the power of Redis, we’ve found
Resque to be a perfect fit for our architecture and needs.
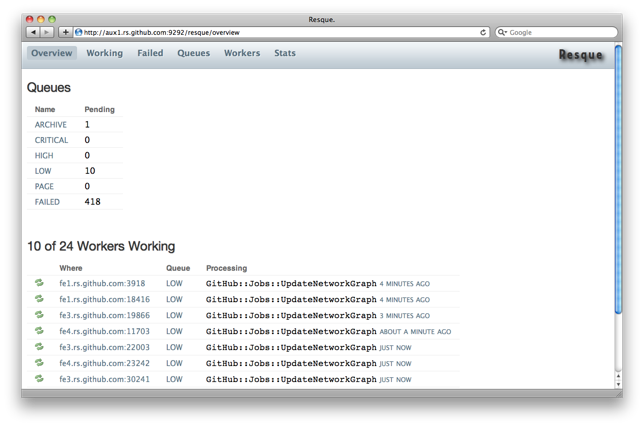
We hope you enjoy it. We certainly do!
GitHub has been awarded the 2024 Axe Accessibility at Scale Award from Deque Systems. Read more about how we’ve implemented accessibility at scale.

Our latest solution to the ubiquitous engineering problem of integration testing in a distributed service ecosystem here at GitHub.

As the year winds down, we're highlighting some of the incredible work from GitHub’s engineers, product teams, and security researchers.