
A short guide to mastering keyboard shortcuts on GitHub
Say goodbye to constant mouse clicking and hello to seamless navigation with GitHub shortcuts.
Say goodbye to constant mouse clicking and hello to seamless navigation with GitHub shortcuts.


We’re asking for feedback on a proposed Acceptable Use Policy update to address the use of synthetic and manipulated media tools for non-consensual intimate imagery and disinformation while protecting valuable research.


It’s the 10th anniversary of our global developer event! Celebrate with us by picking up in-person tickets today. It’s bound to be our best one yet.


As we’re opening up the doors to our final class of this programmatic year, we’re also looking back at our recent graduates and the partners that helped make them a success.

GitHub enables developer collaboration on innovative software projects, and we’re committed to ensuring policymakers understand developer needs when crafting AI regulation.

In March, we experienced two incidents that resulted in degraded performance across GitHub services.
GitHub Copilot increases efficiency for our engineers by allowing us to automate repetitive tasks, stay focused, and more.
Discover the latest trends and insights on public software development activity on GitHub with the release of Q4 2023 data for the Innovation Graph.
Here’s how retrieval-augmented generation, or RAG, uses a variety of data sources to keep AI models fresh with up-to-date information and organizational knowledge.
This blog post is an in-depth walkthrough on how we perform security research leveraging GitHub features, including code scanning, CodeQL, and Codespaces.

In March, we experienced two incidents that resulted in degraded performance across GitHub services.
GitHub Copilot increases efficiency for our engineers by allowing us to automate repetitive tasks, stay focused, and more.
Here’s how retrieval-augmented generation, or RAG, uses a variety of data sources to keep AI models fresh with up-to-date information and organizational knowledge.
GitHub Copilot is a powerful AI assistant. Learn practical strategies to get the most out of GitHub Copilot to generate the most relevant and useful code suggestions in your editor.
As we’re opening up the doors to our final class of this programmatic year, we’re also looking back at our recent graduates and the partners that helped make them a success.
Game Bytes is our monthly series taking a peek at the world of gamedev on GitHub—featuring game engine updates, game jam details, open source games, mods, maps, and more. Game on!
Game Bytes is our monthly series taking a peek at the world of gamedev on GitHub—featuring game engine updates, game jam details, open source games, mods, maps, and more. Game on! 🕹️

It’s the 10th anniversary of our global developer event! Celebrate with us by picking up in-person tickets today. It’s bound to be our best one yet.
A quick guide on the advantages of using GitHub Actions as your preferred CI/CD tool—and how to build a CI/CD pipeline with it.
GitHub Copilot is a powerful AI assistant. Learn practical strategies to get the most out of GitHub Copilot to generate the most relevant and useful code suggestions in your editor.
In this prompt guide for GitHub Copilot, two GitHub developer advocates, Rizel and Michelle, will share examples and best practices for communicating your desired results to the AI pair programmer.
On March 13, we will officially begin rolling out our initiative to require all developers who contribute code on GitHub.com to enable one or more forms of two-factor authentication (2FA) by the end of 2023. Read on to learn about what the process entails and how you can help secure the software supply chain with 2FA.
When the GitHub Copilot Technical Preview launched just over one year ago, we wanted to know one thing: Is this tool helping developers? The GitHub Next team conducted research using a combination of surveys and experiments, which led us to expected and unexpected answers.
A picture tells a thousand words. Now you can quickly create and edit diagrams in markdown using words with Mermaid support in your Markdown files.


Say goodbye to constant mouse clicking and hello to seamless navigation with GitHub shortcuts.
GitHub-hosted runners now support Azure private networking. Plus, we've added 2 vCPU Linux, 4 vCPU Windows, macOS L, macOS XL, and GPU hosted runners to our runner fleet.
Unlock the secret to organization and collaboration magic with our GitHub Projects tips and tricks roundup.
Now in public beta for GitHub Advanced Security customers, code scanning autofix helps developers remediate more than two-thirds of supported alerts with little or no editing.
Learn how we’re managing feature releases and establishing best practices within and across teams at GitHub using GitHub Projects.

Our most advanced AI offering to date is customized to your organization’s knowledge and codebase, infusing GitHub Copilot throughout the software development lifecycle.

Whether you're coding up a storm or cooking up code, building a controller function with AI is your secret sauce to a flavorful app.
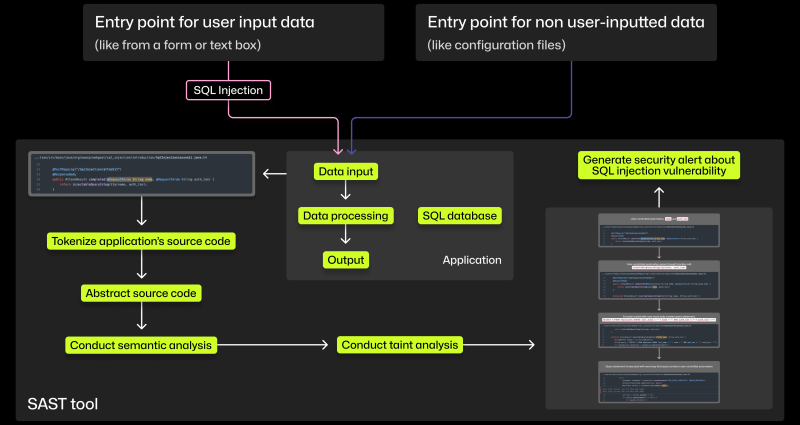
More developers will have to fix security issues in the age of shifting left. Here, we break down how SAST tools can help them find and address vulnerabilities.

In practice, shifting left has been more about shifting the burden rather than the ability. But AI is bringing its promise closer to reality. Here’s how.
In this post, I’ll look at CVE-2023-6241, a vulnerability in the Arm Mali GPU that allows a malicious app to gain arbitrary kernel code execution and root on an Android phone. I’ll show how this vulnerability can be exploited even when Memory Tagging Extension (MTE), a powerful mitigation, is enabled on the device.
With push protection now enabled by default, GitHub helps open source developers safeguard their secrets, and their reputations.
Repo-jacking is a specific type of supply chain attack. This blog post explains what it is, what the risk is, and what you can do to stay safe.
Learn to find and fix security issues while having fun with Secure Code Game, now with new challenges focusing on JavaScript, Python, Go, and GitHub Actions!


This blog post is an in-depth walkthrough on how we perform security research leveraging GitHub features, including code scanning, CodeQL, and Codespaces.

A discussion about how tech is aiding organizations fighting for gender equality, what it means to be a woman in tech and the world today, and advice on how we all move forward.


Game Bytes is our monthly series taking a peek at the world of gamedev on GitHub—featuring game engine updates, game jam details, open source games, mods, maps, and more. Game on!

Game Bytes is our monthly series taking a peek at the world of gamedev on GitHub—featuring game engine updates, game jam details, open source games, mods, maps, and more. Game on! 🕹️


The first Git release of 2024 is here! Take a look at some of our highlights on what's new in Git 2.44.


Get excited for this month's Release Radar. Maintainers were hard at work this past month, shipping major updates for you all. Read on for our top staff picks.

In March, we experienced two incidents that resulted in degraded performance across GitHub services.
In February, we experienced two incidents that resulted in degraded performance across GitHub services.
With this version, customers can choose how to best scale their security strategy, gain more control over deployments, and so much more.
Celebrate the first year of GitHub Fund, our first investments, and a brief look of where we’re going.
During the second cycle of Git Commit Uruguay, students learned the basics of AI and built their own AI-powered projects.
Unlock your full potential with GitHub Certifications! Earning a GitHub certification will give you the competitive advantage of showing up as a GitHub expert.
We’re asking for feedback on a proposed Acceptable Use Policy update to address the use of synthetic and manipulated media tools for non-consensual intimate imagery and disinformation while protecting valuable research.
GitHub enables developer collaboration on innovative software projects, and we’re committed to ensuring policymakers understand developer needs when crafting AI regulation.
Discover the latest trends and insights on public software development activity on GitHub with the release of Q4 2023 data for the Innovation Graph.

GitHub has been awarded the 2024 Axe Accessibility at Scale Award from Deque Systems. Read more about how we’ve implemented accessibility at scale.
Our latest solution to the ubiquitous engineering problem of integration testing in a distributed service ecosystem here at GitHub.
As the year winds down, we're highlighting some of the incredible work from GitHub’s engineers, product teams, and security researchers.