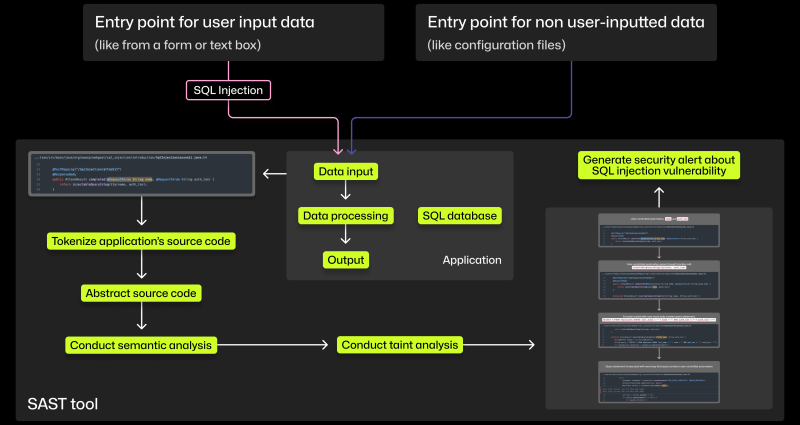
Securing millions of developers through 2FA
We’ve dramatically increased 2FA adoption on GitHub as part of our responsibility to make the software ecosystem more secure. Read on to learn how we secured millions of developers and why we’re urging more organizations to join us in these efforts.